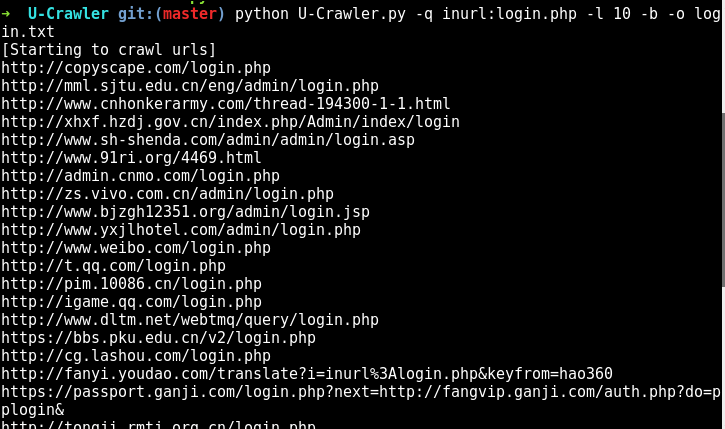
Usage: U-Crawler.py [-q] query [--limit] number [-o] filename
Options: --version show program's version number and exit -h, --help show this help message and exit -q QUERY, --query=QUERY The query of search engine. -l LIMIT, --limit=LIMIT The limit of each search engine. -o NAME, --output=NAME If not use -o,the filename of output is time string. -b, --baseurl The url of writing in file,if it is set,the url will remove path and param.